Abstract
Reconstructing 3D from a single view image is a long-standing challenge.
One of the popular approaches to tackle this problem is learning-based methods,
but dealing with the test cases unfamiliar with training data (Out-of-distribution; OoD)
introduces an additional challenge. To adapt for unseen samples in test time,
we propose MeTTA, a test-time adaptation (TTA) exploiting generative prior.
We design joint optimization of 3D geometry, appearance, and pose to handle OoD cases.
However, the alignment between the reference image and the 3D shape via the estimated viewpoint could be erroneous,
which leads to ambiguity. To address this ambiguity, we carefully design learnable virtual cameras and their self-calibration.
In our experiments, we demonstrate that MeTTA effectively deals with OoD scenarios
at failure cases of existing learning-based 3D reconstruction models and enables obtaining a realistic appearance
with physically based rendering (PBR) textures.
MeTTA
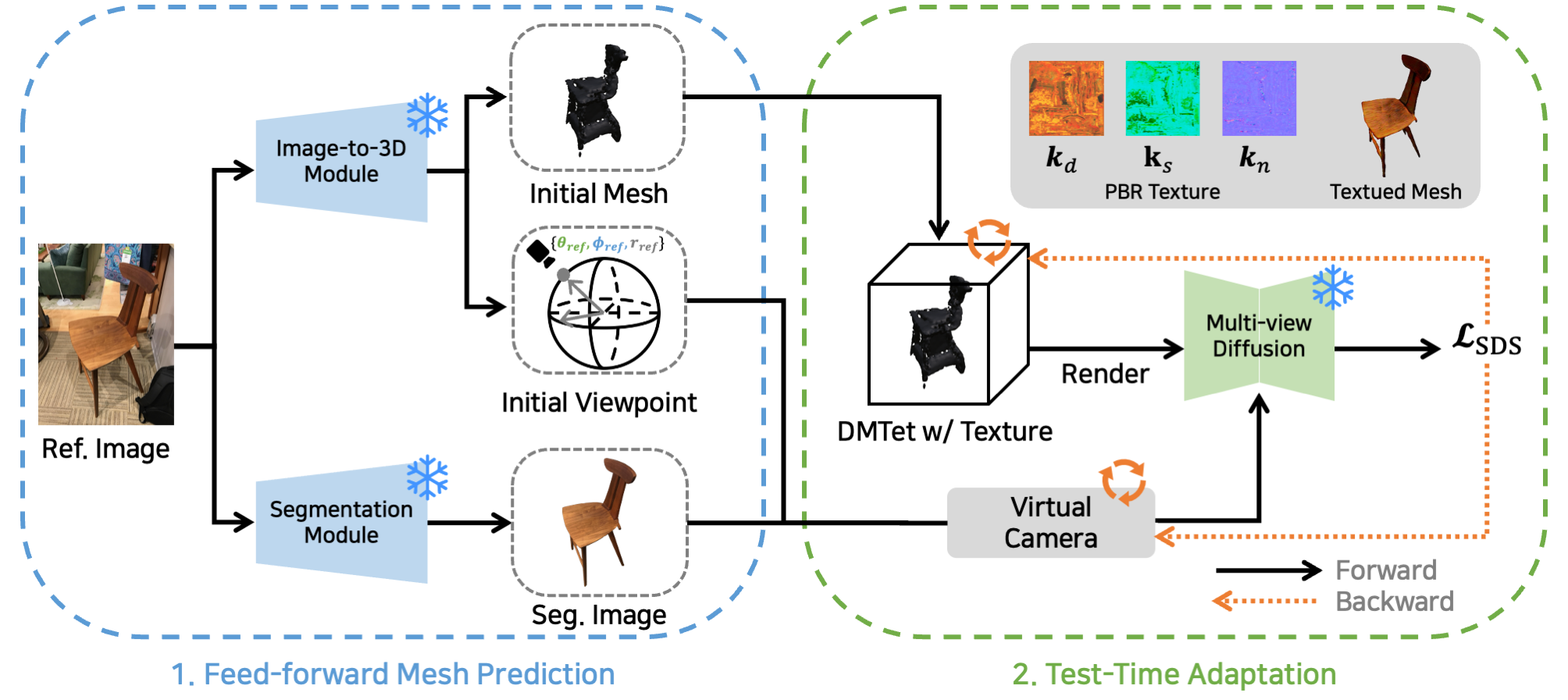 We propose a test-time adaptation pipeline to reconstruct a
3D mesh with PBR texture from a single-view image. “Ref. Image” refers to the reference
input image. “Seg. Image” refers to the object-segmented image from “Ref. Image”.
We propose a test-time adaptation pipeline to reconstruct a
3D mesh with PBR texture from a single-view image. “Ref. Image” refers to the reference
input image. “Seg. Image” refers to the object-segmented image from “Ref. Image”.